About a month and a half ago, we released Khet 2.0 on Steam. After a few updates (fixes & new features) then last weeks release of the ‘Eye of Horus’ Beam Splitter expansion… we’re spending part of our time on our next game: Reversi!
It will be on Steam and we plan to support PC, Mac, and Linux at launch & we currently have no plans for any DLC.
If you’ve been following along on our @BlueLineGames twitter account, this might not be a huge surprise to you. We were tweeting a picture of our passing unit-tests in mid-summer. Yup, while we were ironing out the details of the licensing on Khet, we did about a month of work on Reversi! So we’re off to a great head-start.
As an indie-dev, releasing a game in the middle of the holiday season seems a bit quixotic, so we’re not going to rush it. In parallel, we’ll be doing upgrades to add new features to our engine – which will benefit Reversi as well as our already-released games Hive and Khet 2.0.
Some may be wondering about why we’re going with the classic “Reversi” name rather than the more modern licensed name. Honestly, we like the newer name & the community that’s been built around it. We spent months chasing after that license and we want to (and think we may) get it one day. In the meantime… Reversi! 🙂
We recently released Khet 2.0 for PC, Mac and Linux and have been working on the Beamsplitter expansion piece (among other things).
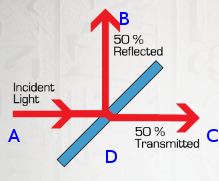
The Beamsplitter piece lets the laser pass through and also reflects it at a 90-degree angle. This changes the concept of the laser from being a linked-list to being a directed-graph. This makes most of the code become recursive, but also leads to an interesting challenge: easily detecting infinite-loops.
We could use a heavy-handed approach of storing a record of every beamsplitter and every side that a laser comes out of, then comparing it to results of any new beamsplitter hits, to see if anything changed. However, it turns out there are some generalities that may let us do it more gracefully.
In this diagram, the laser source at “A” gets reflected to “B” and also travels through to “C” while the direction “D” is not affected yet. Regardless of the rotation of the beamsplitter, if we follow this key, the following rules will always be true if a laser hits the Beamsplitter again on any of the 4 surfaces:
“A”: If “A” is hit (which I’m not sure is possible since I think it would require a loop to already have ended), then nothing changes. The inbound laser can be considered a “closed loop” ending.
“B” & “C”: If either of these spots are hit, then there will be a new exit-point at “D”. Any future hits to this same Beamsplitter will be “closed loops” regardless of where they hit.
“D”: Hitting here has used up the last junction and is a “closed loop”. Any future hits to this same Beamsplitter will be “closed loops” regardless of where they hit.
Also convenient is that we only need to detect loops at Beamsplitters. This will let some laser-segments overlap each other occasionally, but they will only overlap once before hitting a Beamsplitter, so there is no danger of infinite-looping as long as this logic is enforced at each Beamsplitter.
That was just a random tech rambling. Hope it was interesting! 🙂
EDIT: Incidentally, I finished writing the laser logic and the brute-force approach ended up being really simple & with no real overhead so I just went that way. Oh well, I was proud of myself while I thought it mattered. ;).
Yesterday we launched our second game: Khet 2.0 on Steam. As is usual with a Steam launch, we get a ton of requests (a couple dozen a day, probably) emailed to us for free “Review” copies for press.
Red Handed
I often had a sense that some of these people were maybe not legit, but life is busy so who has the time to really look into it? Well, my curiosity finally got the better of me. When a handful of requests in a row all seemed suspicious, I decided to compare the “from” email address to what was on YouTube and I sent a response to the real youtuber’s address. He confirmed that he was being impersonated.
So what?
Part of why I didn’t look into this before is that I figured the worst that could happen is some pirate (who probably wasn’t going to buy my game) would get my game for free. Turns out though, it’s a little more nefarious. Other devs have tracked these keys down to G2A* which is basically a market for illegally reselling keys**. So now people are taking keys for free and selling them to real gamers who are willing to pay money for your game. Developer makes a game… gamer pays for game… thief gets the money (and G2A gets a cut).
Therefore, if you don’t check into people at all before sending keys you’ll probably lose a few sales (not a huge deal) but you’ll be giving money to both the sketchy G2A as well as encouraging the theft to go on which takes money from away from other devs (and many of those devs can’t afford to lose a few sales).
Developer makes a game… gamer pays for game… thief gets the money (and G2A gets a cut).
Simple fix
Fortunately, once aware of the scam, this is super-easy to fix.
Are you a gamer? Don’t buy from G2A.Are you a dev? Don’t “reply” to send the keys via email… instead go to the youtube page of the person and send it in a YouTube message (or to their listed email address).Are you a YouTuber? Add you email address to your about page (youtube protects it from spambots) and be prepared to get some keys in your YouTube messages instead of email sometimes. Sorry for any inconvenience (I know inboxes can be a mess)!Do you care? Spread the word. If gamers stop accidentally buying stolen keys & devs mainly send the keys out via YouTube, the thieves will move on to easier targets than indie games.
Boom, solved. It just takes a small process fix to avoid the issue entirely. Gamers are not your enemies. YouTubers are not your enemies. You don’t have to start being tightfisted with keys or anything like that. We just gave away over 100 games via @IndieGamerChick about a week ago for #GamesMatter and that went great!
Anywho… sorry for the slightly negative post. We love gamers! We love game devs! We love YouTubers & Let’s Players (and give them full permission to monetize videos about our games)!
Now back to regularly scheduled gaming! 😀
– Sean
*: Disclosure: I know the author of the Polygon post in real life.
**: This statement has not been evaluated by the FDA. G2A claims it is legitimate because you could have an unredeemed Steam key for some legit reason (maybe if it was a gift?) but it is a widely held belief that most keys on there are either taken from bundles (which is against the terms of service of most bundles & of Steam), soaked up from contests, or stolen in the fashion described in this article.
Our second major release, “Khet 2.0” is now live on Steam! Buy it once and play it for PC, Mac, and Linux.
Hit that link to the Steam page to read all about the game. Here I’ll just wax poetic about our history launching it…
…
Before we (Sean & Geoff) started making games together, we had another startup that we worked on together. After a while we sold that company, but even back then we talked about making video games someday. We kicked around all kinds of ideas and Khet was one of the earlier ones. I think Geoff actually introduced me to the game years before, at RIT, but my memory is a bit fuzzy on when he first told me about it.
I started reading a ton of indie game blogs in 2007 to learn more. It seemed like a really brutal industry & I didn’t want to go in blindly, take one swing for the fences and then have to go back to a day-job if it wasn’t a hit. Four years later when BlueLine couldn’t be postponed any longer, my devious plot to take gaming by storm was based around creating a number of digital versions of award-winning board games. We had two games in mind that we thought we could do great. This is a for-reals photo from December 2011 after Geoff and I just finished playing board games at an Eat N’ Park late one night (they’re awesome for tolerating that kind of thing):
With today’s launch, we finally managed to ship the second of those games that we were playing nearly 3 years ago and dreaming of converting to a digital version!
It’s been a long ride, and we even had a false-start. We got about half-way making Khet for Xbox 360’s indie store when Microsoft announced that it would stop supporting XNA (the language used to make those games) and sales immediately tanked on that whole marketplace. We had to shelf the game for several months as we switched gears to port Hive – and our entire board game engine – to run on PC, Mac, and Linux with Steam networking instead of Xbox LIVE. As you can imagine, it was a bit tricky getting the PC, Mac, Linux license from the game designer after not shipping on Xbox 360. We shipped today though… reputation restored! 😀
That’s our very long backstory that’s probably mainly interesting to others devs or those thinking about starting some business (possibly gaming related) of their own.
If you have any questions, leave us a comment! We’re allowed to share most info. Now, go buy Khet 2.0 on Steam! 😀
We just released a big update to Hive which included some great visual changes as well as a number of AI improvements. One of the interesting AI changes was the addition of a bit more randomness to the AI’s decisions, with minimal impact on the skill of the AI. This is the 2nd part in a 2-post series on the topic. If you haven’t read the first post of the series, I recommend that you at least skim it first.
Randomness on all moves
Even with a large number of random openings, it would be possible to run into similar situations down the road that would play out time and time again (Battlestar Galactica style). Since this repetition would lead to predictability but most randomness decreases the skill-level of the AI, we had to strike a balance. In order to make it so that full games diverge from each other significantly, but without weakening the AI too much, I came up with the concept of a “randomness quotient”. I don’t know if this already exists in Game AI or not, but it seems to be a good solution and that was the most appropriate name I could think of for it.
“Randomness Quotient” explained
The “randomness quotient” is a setting that will increase the randomness of the choices as its value decreases. Specifically, if the randomness quotient (which we will represent with the variable “Q”) is 7, then the engine will choose a ply other than the best move about 1/7 times (which is “1/Q” times). Of those instances where the best-scored ply is not chosen, then the second-best move will be chosen 1/Q times. Therefore, the odds of getting to the second best move and still choosing to consider the third-best scored move is ((1 / Q) / Q) which is the same as (1 / (Q ^ [move-number])). To figure out the opposite number (the odds of choosing move number N, rather than the odds that we’ll skip past it) we’d use a numerator of (Q-1). For example, the 8th best move would be chosen once in approximately ((Q-1) / (Q ^ 8)) moves. The more general equation is: ((Q-1) / (Q^N)) where Q is the randomness quotient, and N is the move number (as ranked by the heuristic evaluation method so that move 1 scores the best, move 2 scored the second best, etc.).
Even with a fairly high amount of randomness – such as a Q of 2, remember: low Q means high randomness – we would only see a move as bad as the 8th move in 1 out of every (1/(2^8))= 256 moves.
These occasional less-than-stellar moves are essentially simulating a human player occasionally losing concentration.
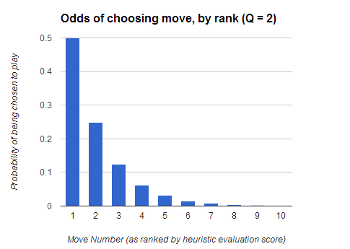
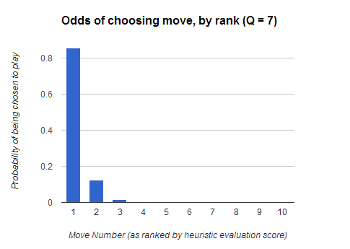
In case the math was a bit confusing there, we can show the effects of this algorithm visually. Each bar in the chart is the move-number where the moves are ranked from the best-scoring on the left to the worst-scoring on the right.
In the first chart, there is a very low randomness quotient of “2” which is NOT recommended in realistic play, but it’s still a great example to visualize how this works. You’ll notice the first move is chosen 1/2 of the time. Since the other 1/2 of the moves are also cut in half, then the second-best move (move index 1) is only chosen in 1/4 of the instances.
In this second chart, we have a higher randomness quotient of 7 which represents a more realistic setting. This setting doesn’t add a ton of randomness to any given move, but over the length of a normal game, this should introduce enough randomness to steer any similar games apart from each other. As you may have recognized, these charts are an example of exponential decay.
In our code, we used lower Q values to give more randomness to weaker levels of AI to “nerf” them a bit, while giving them more variation at the same time. The higher levels of AI still have a modestly high randomness quotient since we want a little randomness – currently Q is around 8 or 9 – but we may continue to tweak that from experience.
Randomness Quotient pseudocode
This is almost the exact code from our Minimax engine where we implement randomness based on the Randomness Quotient. It’s not that much code!
// At this point, the Minimax engine has scored some plies
// and stored them and their scores in topLevelScoresByPly.
List<KeyValuePair<Ply, double>> plyPairList = topLevelScoresByPly.ToList();
// Sort the plies descending by their scores (best score at index 0).
plyPairList.Sort((x, y) => y.Value.CompareTo(x.Value));
// Apply the RandomnessQuotient so that the best-scored ply is not guaranteed to be chosen, but is still
// exponentially more likely than the second which is exponentially more likely than the third, etc.
int plyIndex = 0;
while ((plyIndex < (plyPairList.Count - 1)) && (0 == randGen.Next((int)RandomnessQuotient)))
{
plyIndex++;
}
if (plyIndex > 0)
{
Logger.log(LogLevel.INFO, "RANDOMNESS! Skipping the best (0th) ply and chosing ply index " + plyIndex +" instead.");
}
// Grab the ply that the Randomness Quotient has chosen.
theChosenPly = plyPairList[plyIndex].Key;
chosenPlyScore = plyPairList[plyIndex].Value;
Conclusion
The addition of randomness to the AI engine has greatly increased the replay-value of the AI in Hive. Hopefully this concept can be useful to some other developers as well. This change was released as a free update two days ago, along with a significant batch of visual updates and about a half-dozen other AI improvements that we’ve made over the past week or so. If you have the game, check them out… if you haven’t bought Hive yet, please support us by grabbing your copy on Steam today!
As always, please let us know if you have any feedback about the changes in Hive, or if you have any questions about this post! If you’ve implemented randomness in your own AI in another interesting way, please leave a comment for the other readers – and myself – to learn from.
Today we are happy to say that we have launched a new build of Hive. This build has a number of AI tweaks that Sean mentioned in the previous post and will be talking more about in an upcoming post (edit: now posted). Another large piece of this update is an overall upgrade to the in-game look. We have received a large amount of feedback of how people would like to see the game represented, and we have listened.
First and foremost, we have upped the overall realism of the game pieces by making them to scale with the real life game pieces. The dimensions of the in game tiles should mimic the real life tiles precisely in proportions. This gives you a much more familiar look. We also have set the initial orientation of insects on the tiles to match the real world tiles to add to the familiarity.
Another huge update you will notice immediately is that we have added a virtual tabletop. No longer do the pieces seem to float in space, they now rest on an unending virtual wooden table complete with shadows, giving a much more real world feel. We hope in the future to expand this even a little further and allow you to select from a variety of surfaces to play on. We may even go as far as allow custom table tops.
Also, to bring the game a little further into the real world, we switched from an orthographic camera to a perspective camera to give the game a little more sense of depth.
Finally, we tweaked the game piece HUD just a bit to give the game a little more room to breathe and to show off the new tabletop below just a little bit.
We make a habit of asking great Hive players to give us feedback on the AI for our Steam version of Hive . Now that the AI has become pretty formidable, a suggestion we started hearing a few times was that the AI wasn’t random enough. This allowed players to basically memorize outcomes and they found themselves replaying any moves that worked in the past, rather than playing to win.
As I mentioned in my ECGC 2013 talk, an important concern in “real-world”/commercial game AI – as opposed to just getting optimal results in a lab – is to make sure that your AI teaches players to get better at the game rather than how to get better at just beating your AI.
When to use Randomness
In perfect strategy games (those with no luck), a completely random move is highly unlikely to be good. Conversely, even with great AI: if the AI is imperfect, then having little-to-no-randomness makes it easy for players to memorize and exploit any weaknesses. Your first reaction might be to just assume we should make perfect AI. However, for sufficiently-complex games such as Hive and Chess, the possible outcomes are more numerous than the atoms in the universe, so we’re likely to be relegated to imperfect AI forever (or at least until we have decent quantum-computers).
Not only does complete randomness lead to weak decisions, but almost* any randomness generally leads to slightly worse decisions. If you aren’t using randomness, you always chose the best-scoring move. Due to this trade-off of efficacy vs. randomness, I would not recommend adding much randomness to your AI until it is already very good.
Randomness in Openings
Players who played dozens of games in a row against our AI quickly became cognizant of patterns and vulnerabilities in the AI’s openings. Once they discovered a way to make the AI have a weak opening they found themselves constantly replaying those openings and regardless of what happened after, the AI couldn’t recover from that bad of a start.
Since variation in openings was crucial to preventing the AI from getting in a rut, we added a fair amount of randomness.
How it was before:
Originally, we used a weighted probability to figure out which Hive tile to place. The second ply was always placing a Queen, off-center of the first piece (not inline). The third move and beyond were all calculated by our minimax engine.
How it is now:
Hive “C”, “I”, “L”, and “Z” shaped openings.
We use a weighted probability for the first and second pieces. The second piece is still quite likely to be a Queen (it’s a very solid choice) but it won’t always be a Queen. The location of the second placement is now completely random. In Randy Ingersoll’s book, Play Hive Like A Champion, he named the openings based on the shape of the tiles. Normal openings can be laid-out like a “C”, “I”, “L” or “Z” (there are also “F” and “J” openings, which are just rotated versions of the “L”). If a player chooses not to place their queen by the second move, then the opening is called an “X”. The “X” isn’t considered a very good opening, but all of the possible openings can now be done by the slightly random AI; the weightings are just tuned so that it will be pretty rare for the AI to play “X”.
In addition to the decent randomness on the second move, we also expanded it so that the third-move (which is computed using the minimax engine) has a high degree of randomness. 1/2 of the time, the best scoring move will not be chosen, and in 1/2 of the those instances, the second best scoring move won’t be chosen either. The next post will explain more about this type of randomness.
Randomness on all other moves!
This is a little more complicated/mathematical/technical so I’ve split it into another post to avoid tiring you out with this already-long post! It should be posted in the next day or two. edit: it’s posted now.
Conclusion
The addition of randomness to the AI engine has greatly increased the replay-value of the AI in Hive. Hopefully this concept can be useful to some other developers as well. This change is going to be released as a free update in the next couple of days, along with a significant batch of visual updates and about a half-dozen other AI improvements that we’ve made over the past week or so. Keep your eye out for the update on Steam! EDIT: The update has been released!
As always, please let us know if you have any feedback about the changes in Hive, or if you have any questions about this post! If you’ve implemented randomness in your own AI in another interesting way, please leave a comment for the other readers – and myself – to learn from.
Thanks!
*: “Almost” because you can get a small amount of randomness from randomly choosing between any moves that tie for the “best move”, but that’s unlikely to happen very often and will still yield nearly-identical moves in many cases – eg: moving one pawn in Chess instead of its mirror opposite.
While creating the Steam version of the popular board game Hive, it became clear that normal methods of on-screen debugging weren’t going to be in-depth enough.
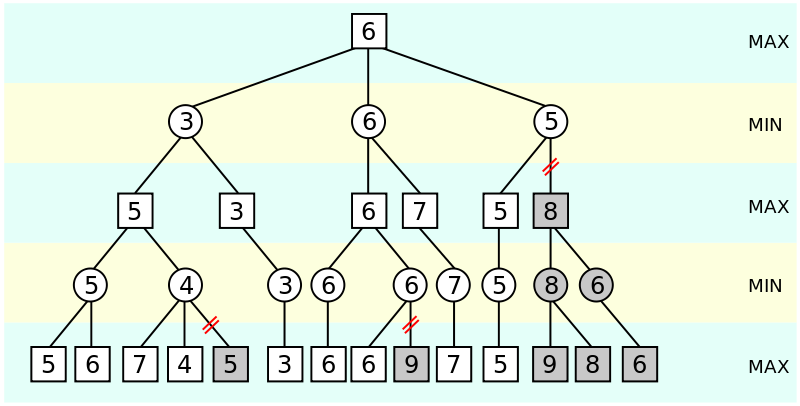
Alpha-beta pruning of a small Minimax game tree.
Most AI for 2-player abstract-strategy games probably uses the tried-and-true Minimax algorithm. It works just how you’d think AI would work: you look at a tree of all of the possible board positions that you could get to (and all positions you get to from there, etc.) and score them. It can get a little more complex on top of that, but the basics are really straightforward.
While the Minimax algorithm is very general-purpose, the scoring function that you use to evaluate each position is game-specific. Debugging that scoring function (called a “heuristic evaluation function” in technical lingo) can be tricky, especially since it is very hard to see an entire game-tree at once. The small tree in the first picture above is used for teaching minimax, but is unrealistically small for real games. As an example, even a very simple game like Tic-Tac-Toe would have 3 possible moves right away (it would be 9 moves, but the board is symmetrical, so there are only 3 actual different moves). Looking at this tic-tac-toe tree, you can see that even this extremely-simple game’s tree grows quite large by the third layer.
Complexity of real Game Trees
First two plies of Tic-Tac-Toe game tree
Let’s put that in perspective compared to other games: The number of moves that can be done per level is called a “branching factor“. In the tic-tac-toe example, the branching factor at the start of the game is 3. After moving, the branching factor is 2, 5, or 5, depending on which move is made. In chess, your first move can be one of 20 possibilities: 8 pawns (each with 2 different moves) and 2 knights which have 2 possible moves each. From there, the possibilities change very quickly. Due to this variability, when discussing games we tend to focus mainly on the average branching factor. The average branching factor of tic-tac-toe is 4, for chess it’s 35, the value for Hive is currently unknown but I’d estimate it between 40 and 50.
The need for a good visualizer
For a game such as Hive, to have the AI look 3 levels deep, you’d have (50^3) = 125,000 nodes on the third level of the tree. Even if we limit the branching factor (which we do in our AI) the number of nodes is quite large. At the time of this writing one of our AI levels limits to a branching factor of 30. So (30^3) = 27,000 nodes. Needless to say, that tree won’t fit on most computer screens, so it would be hard to debug it all at once.
Therefore, we need a different way to visualize what’s going on. When debugging a heuristic evaluation function, it’s important to know the score throughout the tree, how the score worked its way up each level, and it also helps to be able to see a detailed view of how the AI scored the nodes. Keep in mind that only the scores on the bottom level of the tree are actually used to be the final scores of the path to that node. However, when we limit the branching-factor, that involves giving a preliminary score to each node and sorting all of the sibling nodes in any given level of the tree, before traversing to their children. This way, even though many moves may be skipped in a given level of the tree, the odds are high that the most important moves are being evaluated. Due to this pre-scoring, it is helpful to have detailed scoring information on every node in the tree.
In addition to seeing the nodes in a current level, it would be helpful to have pointers to which layers of the tree are maximization or minimization steps so that you don’t have to keep as much information in your head. This way, you can examine any node in the tree and tell where it got its score from (eg: it’s children) and how its score is being used by its parent-node if it has one.
Our solution
Minimax AI Visualizer – click to enlarge
We wanted to be able to run the AI in our game’s debug-mode, then create a log-file and view it easily. After looking around, it seemed that a very simple solution would be to dump some JSON in a format that the Javascript InfoVis Toolkit (JIT) could load, then create a tool to render a “Space Tree” which expands and collapses as needed.
I started with the SpaceTree demo from JIT and just modified it from there. Features:
Loads data from a JSON file by default, but you can paste new JSON into a text-box to create a new tree (or use the text-box modify the existing tree).
Colorized to easily show which steps are Maximize steps or Minimize steps
Each node says what ply it represents to get to that node, and the final score that node ended up with.
The mouse scroll-wheel lets you zoom in and out
Hovering over a node brings up a detailed tool-tip bubble with the breakdown of each of the scoring-factors that were used to come up with the pre-scoring for a node – or the actual scoring, in the event that it’s a leaf-node.
Hovering over the Root Node brings up a tool-tip bubble with detailed info on the entire run of the AI: how many nodes were evaluated, how long the AI ran, how many total prune events there were, etc..
Each time there is a prune event (from the alpha-beta pruning), there will be one node which indicates the entire number of sibling nodes that were pruned at once.
If you want to use the same tool to visualize the progress of your own AI, all you need to do is have your code output JSON in the same format that’s used in the textarea below the graph, then paste it into that textarea and hit the “Load Tree” button.
Outcome
Being able to more quickly track-down some of the weird decisions that the AI was making, let us drastically improve the AI in only a few days of work. The example that’s embedded in the Visualizer is from before most of the changes, but that shouldn’t matter since it’s just showing how it works. We’ve had some very good players helping us debug it, and one of the recent World Champions said that the top level of AI made him force a draw. We’re getting there!
If you want to see the AI in action, check out Hive on Steam.
If you have any questions about the Visualizer or about our AI, let me know in the comments!
We are downright giddy to announce… Hive is coming to Steam! It’ll be the same great game as on Xbox, but will have a few extra bonuses:
Game will track over 40 stats on Steam and you can earn 30+ Steam Achievements.
There will be 2 new levels of AI. Since even low-end PCs are typically a lot more powerful than Xbox 360s (because those are now quite old) this gives an opportunity to have the AI make much, much better moves in the same amount of thinking-time.
Seamlessly switch between using your mouse/keyboard or playing with a gamepad.
The first release will be on PC, but we hope to release it on both Mac and Linux soon afterward. Buying the game means you’ll get a Steam key once the game is released. This will allow you to play on any/all of the platforms once each platform is available (eg: if you buy now, you can play on PC as soon as that’s released and you do not have to re-buy it to play on Mac when the Mac version comes out).
To give a better deal to our loyal fans, we’re offering a 30% discount on pre-orders! Get it below using the Humble Widget (powered by the “Humble Bundle” team):
If you can’t see the widget above, you can click this link to pre-order Hive. Have an old computer? If you’re worried about compatibility, please check the minimum requirements on the Steam Store page (scroll down a bit or search for ‘System Requirements’).
UPDATE: You can now buy this game on Steam ‘Early Access’ which will let you play the incomplete beta immediately, and you will automatically be upgraded to the full version once it is released. Please click ‘add to card’ on the Hive page on Steam.
Like being kept in the loop? Join the mailing list to keep up with our announcements:
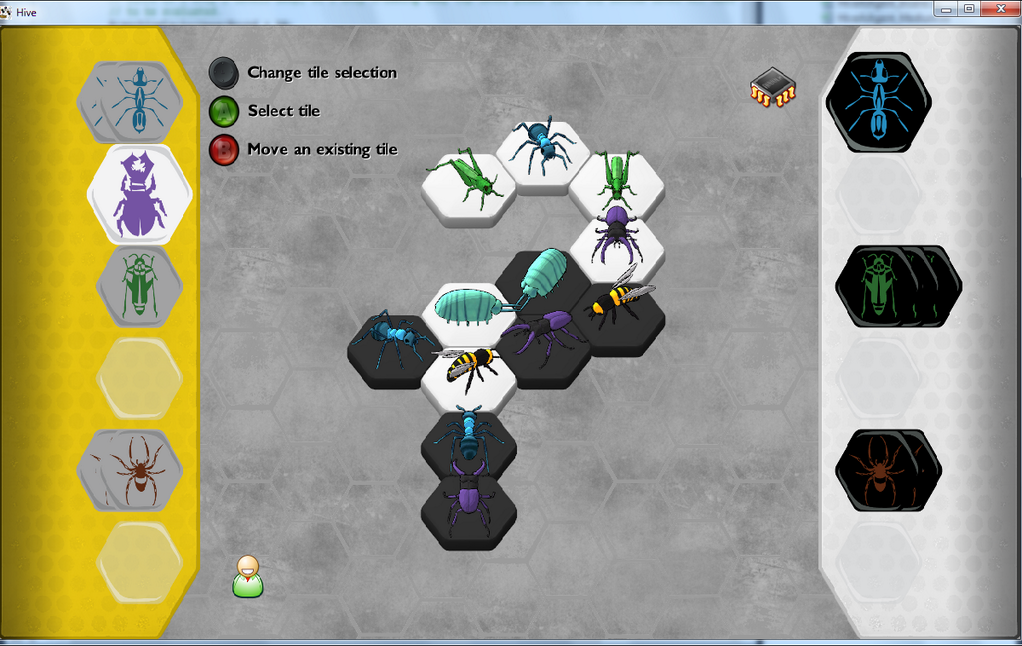
There’s been a lot of excitement around the upcoming release of the Pillbug expansion for Hive.
We have great news: if you buy the Pillbug expansion when it comes out, the package will have a code on it which will let you unlock the Pillbug in the Xbox version of Hive!
While this is a pretty big update… we have even better news coming up soon. Join the mailing list to keep up with our announcements: