If you’re not familiar with BlueLine Games, we’re best known for making digital versions of board games, and Lost Cities by Reiner Knizia is the next game we’re working on. Below is my draft at a potential notation that I think would work well.
LOST CITIES STANDARD NOTATION SPEC v1.0 – Sean Colombo 20161007
Placement Notation
In Lost Cities, there are two types of placements that a player can make on their turn. They can either place a card from their hand onto one of the five expeditions, or they can discard a card to one of the five expedition spaces. Placements shall take the format:
[CARD COLOR LETTER][CARD NUMBER OR “H” FOR HANDSHAKE]<[D FOR DISCARD]>
Where [CARD COLOR LETTER] will be a letter representing the color of the card. Typically this will be the first letter of the color in English, but there will be special cases if additional colors get added which collide with the letters from earlier expeditions. For example, the base pack has Blue represented by “B”, but there is a promo pack that will have Black cards in it, which will be represented by “k”. The letter is NOT case-sensitive, so “k” and “K” are treated the same.
Color
Letter
Red
R
Green
G
White
W
Blue
B
Yellow
Y
Black
K
Note: No color will be assigned “D” because that is reserved for representing the “Draw Pile” in other contexts.
[CARD NUMBER OR “H” FOR HANDSHAKE] is fairly self-explanatory. This is the value on the card that is being placed. The cards have numbers 2 through 10 or a picture of a handshake. The “H” is not case-sensitive so both “h” and “H” should be accepted.
<[D FOR DISCARD]> is an optional suffix, meaning that the placement will discard the card onto the expedition color provided, rather than playing the card onto the track.
Examples:
R3 – Will place a Red “3” from the player’s hand onto the track for the Red expedition.
BHD – Will discard a Blue Handshake card onto the Blue Expedition’s discard-pile.
Draw Notation
The format is simple: [COLOR LETTER TO DRAW FROM OR “D” FOR DRAW-PILE]
This uses the same letters for the colors that were used in Placement notation, except that “D” is reserved for the Draw-Pile.
Game Notation
Each move is numbered, and the move consists of 2 parts, separated by a Hyphen in this format: [PLACEMENT NOTATION]-[DRAW NOTATION]
For example:
R3-D
BHD-D
R4-B
That is a game where Player 1 plays Red 3, then draws from the draw pile. Player 2 discards a Blue Handshake card, then draws from the draw-pile. Then Player 1 plays Red 4, then draws from the Blue Discard Pile.
Conclusion
This notation seems like a good first candidate & should cover all needed cases. There are two things I don’t love about it:
The “D” suffix for discard and “D” for draw-pile both exist. There is no way for them to be confused by a machine since they’re on opposite sides of a hyphen, but very new users to the notation could potentially get confused. Another option could be “X” for discard, but that might not be as intuitive as “D”. I think that an English speaker is likely to be able to look at the notation an existing game using this v1.0 draft I’ve proposed, and infer the entire standard without reading the documentation at all.
It leans heavily on English language for color names and letters from “Discard” and “Draw” even though the game originates from Germany. If “Black” and “Schwartz” shared a letter that made sense to represent the color in both languages (“a” isn’t very representative of either word, but it’s the only letter they share) then I would have chosen that instead of “K”.
Compressed Version
For a quick reminder or pasting into code, here is a compressed version of the standard: [CARD COLOR LETTER][CARD NUMBER OR “H” FOR HANDSHAKE]<[D FOR DISCARD]>-[COLOR LETTER TO DRAW FROM OR “D” FOR DRAW-PILE] (“K” for “Black” expedition)
Let me know in the comments if you have any thoughts about this notation and also feel free to link to your project if you’ve implemented this notation in a product of your own!
When reading a great article from the creators of Soma Water about how they raised $100,000 in 10 days on Kickstarter, the shared the idea of this share-page that they sent to their closest friends & supporters to ask them to share the project with their friends.
The little landing page was cute, functional, and very simple. I thought it’d be great to do something like this for the launch of Othello on Steam. Since the source was all right there & formatted beautifully, I figured it’d be worthwhile to make a PHP script that would output the same kind of page based on a very easy configuration so that non-coders could get that great landing page with very little effort or programming ability.
See it in action
Here is an example of the page in-action, for our recent release of Othello:
(click image to view the page)
Use it for yourself!
Download the simpleShare.zip and unzip it.
*hashes of zip file:
md5: 512EEC59969F051BD1513E05DD24E7B7
sha1: 8314161C9FC4A7FECC583F8B7B290838C13BADE3
If you don’t know what these hashes are for, just ignore them.
In the folder you just extracted, there is an index.php file with configuration code at the top which you have to fill in. The comments will help you figure out what to put there (there is also an example). Open index.php in a text-editor to do the configuration.
Place the entire “share” directory on your webserver where you want the page to be located.
View the “share” page in your browser (the URL will depend on where you have uploaded the directory. For example, we uploaded the “share” directory to the main directory of our bluelinegamestudios.com webserver and the page is located at: http://bluelinegamestudios.com/share
Technical details
All this page should require in order to work is a PHP server and the directory that we provided in the zip file above.
We started by just copying the html/js/css straight-up, then went on to make it configurable and tried to improve various little aspects so that everyone can get a great sharing page without having to mess with it. The original page was made in 2012, so some things were just updated a smidge. Some changes we made:
Made the entire thing configurable at the top of the file so you only need to look in one spot.
Made some slight performance improvements like moving the javascript to the bottom of the page, removing an external HTTP request, and adding caching headers.
Made the single script capable of building the share pages for multiple projects (so you won’t need a separate copy of this tool for each project; just an extra section in the config).
Updated the google analytics code to the more recent code.
If the configuration wasn’t set up yet, hitting the page will show instructions on configuring it.
If more than one project exists, but none was specified in the URL, will show a list of projects.
Please remember that while I made the configurable open-source script, the entire idea and the page design/functionality all came from Soma Water who was kind enough to share it with the world. Check them out. 🙂
If you are in a sharing mood and want to share the project that resulted in us making this page, please check out this page: share Othello.
The tabletop designer of Hive, has just begun releasing his newest game, Tatsu. It’s out in the UK and getting great critical acclaim, and is currently rolling out in mainland Europe and the United States during the summer of 2016.
Since it’s such a new game, there isn’t a standardized notation for moves yet… so in this post I’m proposing the one that we used to make a Steam version of Tatsu.
If anyone has a chance to use this notation for anything, I’d appreciate feedback so that I know if there are any major problems with it.
TATSU STANDARD NOTATION SPEC v1.0 – Sean Colombo 20160131
Space Numbering
The spaces on the board are numbered such that each pair is a single space with a capacity of two pieces.
The notation for spaces is that they are each assigned a single number around the circle. The spaces start with number “1” as the space by the Black mat with the number “1” on it. The other spaces will be numbered increasing clockwise all the way to space “24” which will be to the left of space “1”.
This has the side-effect that all of the spaces near the Black mat will have a number drawn on them which match their actual Space Number, but no other spaces on the board will.
Dragon Notation
The different types of board pieces will be represented by a single letter. The letters will be “V” for Vine Dragons, “W” for Water Dragons, and “F” for Fire Dragons.
Move Notation (Ply Notation)
There are two types of moves in Tatsu: Entering the Arena from the Mat, and moving a Dragon from one Space to another.
All moves have a hyphen separating them. The notation is as follows:
Entrance into the Arena: [Dragon Letter]-[Number of space where it will enter]. Examples: “V-2” when Black moves a Vine Dragon into its middle space. “F-14” when White moves a Fire Dragon into its middle space.
Movement on the Arena: [Source space number]-[destination space number]. Examples “2-5” to move the aforementioned Vine Dragon 3 spaces clockwise, or “14-11” to move the aforementioned Fire Dragon 3 spaces counter-clockwise (anti-clockwise). Due to the rules that the outer piece must be moved if you have two Dragons on the same space, there are no ambiguities that require more information than just the source-space and destination space.
Turn Notation
When a player rolls the dice, they have anywhere from 0 to 2 moves to make. If they are able to Enter the Arena or to Move on the Arena, they must do so. However, they are not always able to move given the configuration of the board and the results of the dice. When a turn cannot be made, the move will be represented as “0-0”. Each turn will consist of two plies next to each other. For example, an entire turn by black could be:
V-2 2-5
While it is impossible to have a pass, then a move, in certain configurations the player may run out of abilities to take their second turn and a pass would show up like this:
V-2 0-0
In rare cases, a player may be completely unable to move:
0-0 0-0
Game Notation
It’s not really necessary to define this at this point, but I envision that it could be numbered pairs, like this:
1. 2-5 5-7
2. 14-11 11-9
Unlike many Chess notations where each pair represents both players taking their turns, in the Tatsu notation each number would represent one player taking a turn. As the game is an eternal cycle rather than a back-and-forth game, this seems appropriate.
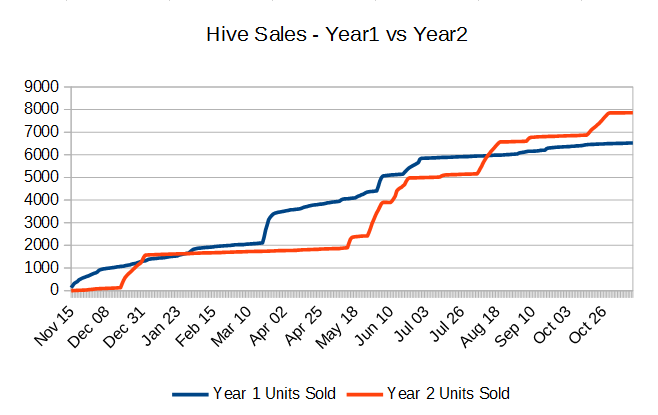
As a small two-person team, we were able to sell more units of Hive in it’s second year after launch than we did in the first – despite living through the “Indiepocalypse”.
This experience flies right in the face of the conventional wisdom of the game sales cycle being mainly one giant launch spike followed by a death-taper-to-zero afterwards.
In this post, I’ll endeavor to tell you what we did to achieve this, and to share some other insights we learned along the way.
Background
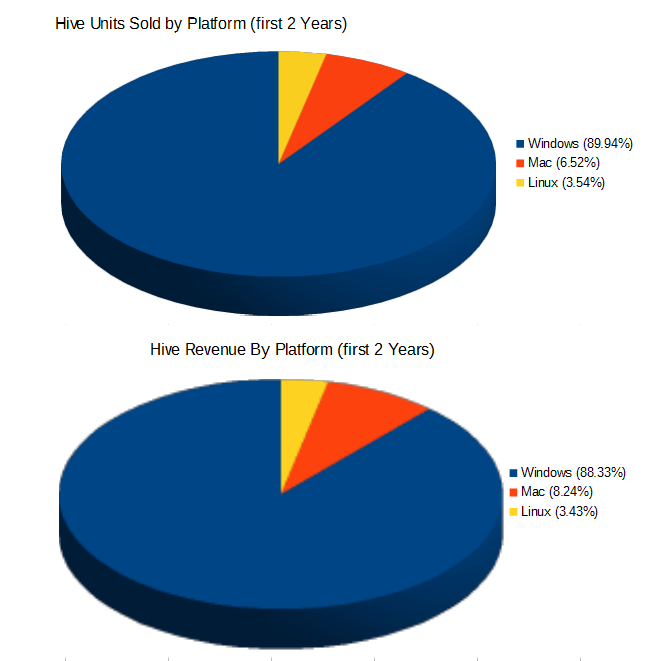
BlueLine Game Studios is a small indie game studio – specializing in making digital versions of amazing board games. The studio consists of Sean Colombo (author of this post) and Geoff Brown. We’re anywhere from 1 to 2 people fulltime; usually one fulltime, one part-time. Years ago, we built a successful web startup together, then 4 years ago we finally became professional game devs with BlueLine Game Studios. After first releasing Hive on Xbox 360, we pivoted and after many more months released Hive as our first title on Steam, just over 2 years ago. Since that time, we’ve also released Khet 2.0, Reversi, and Simply Chess. All of our Steam titles run on Windows, Mac, and Linux.
Requirements
Not all game developers will be able to benefit from what we’ve learned, but a very large number will.
In this flooded market caused by the Indiepocalypse, there are many great games that don’t get nearly as famous as they should (eg: Escape Goat 2, Cannon Brawl, Duskers, Rymdkapsel). Making a great game is not sufficient for it to be successful, but it should be seen as mandatory. Fortunately, we knew when we licensed Hive that the gameplay of the board game was amazing. Our digital conversion seems to be satisfactory to the community and it is currently recommended by 95% of Steam users that review it. There are plenty of articles about how to make good games, and that’s way outside the scope of this article, so we’ll just take it as a pre-requisite.
Additionally, the gameplay should be something that has a lot of replay value (which is a large part of why boardgames are our strategy) and they need not to be “zeitgeisty”. For example, this article wouldn’t be very useful for a game about the 2016 American Presidential election, because it’s unlikely it will perform well in 2017.
What We Learned!
Each paragraph is a different lesson. Subsume their knowledge!
Our single biggest learning was that the only marketing endeavor which drove significant sales spikes was Steam visibility. Significant visibility on Steam comes from several types of events: Early Access Launch, Full Launch, DLC Launches, Mac/Linux Launches, Seasonal Sales (Summer & Holiday), and manually created 1-2 week Discounts.
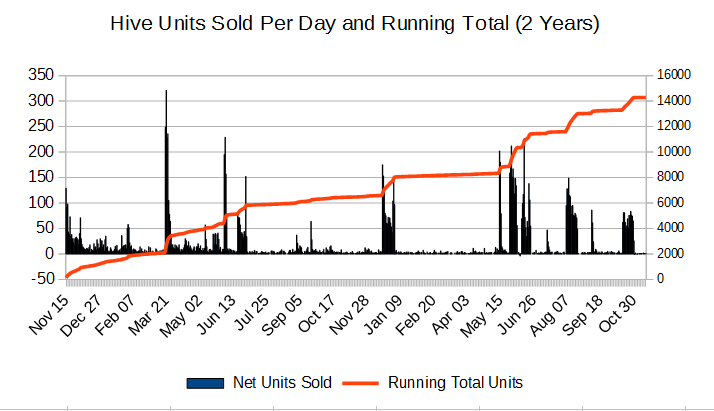
Another huge lesson was that almost all revenue comes from sales-spikes, there are a decent number of ways to cause these spikes, and we must continue to cause them in order to survive. As mentioned before, this contradicts the common assumption that games are very launch-centric and shows that Steam games can be run almost as a service. It’s important to note that if we’d just given up on Hive after launch, our data would have looked like everyone else’s showing that launch was important and the harsh realities of the Indiepocalypse crushed us after that. If we’d stopped investing in Hive after it’s launch month, we’d have missed out on about 70% of the sales we’ve made so-far.
Solid games definitely don’t have to die right after launch. Here’s a chart showing all of the various spikes we were able to cause, and their affect on the running-total:
None of those spikes happened automatically. Every one of them was directly caused by things that we did. Later in the article there is a section which explains the various things we did to cause spikes.
We didn’t do any paid advertising for Hive. We tried several different paid advertisement locations for another game and none of them ended up having a positive return-on-investment as far as we could tell.
I gave talks at the East Coast Game Conference in 2013 (“Turn Based AI“) and 2015 (“Cryptography for Game Developers”) and we also had a booth there in 2015. I also spoke on a couple of panels at PAX Dev 2013. This was a blast and I met a lot of really interesting people that I’ve learned a ton from. This didn’t lead to direct sales spikes, but I still think it was extremely valuable. Sharing what we’ve learned also felt really fulfilling. Hopefully we’ll be doing more conferences, talks, and panels in the future.
We almost entirely neglected press. This could be due to our background in consumer-websites, but after a very short period of posting links to the game on obvious places (facebook, twitter, etc.), we got sucked right back into bug-fixing and new features rather than contacting more press like we should have. We did get a little bit of press from indie reviewers & let’s players. The only press we got from a big outlet was IndieGamerChick re-reviewing the Steam version (she’d reviewed the Xbox 360 version earlier). None of the press that we got caused a visible spike in our sales-data, but we think that’s largely because we didn’t do very much work to get press. The various reviews & videos are all greatly appreciated and they probably lead to some new fans trickling in over-time but just didn’t cause a visible, instant spike in sales so they’re challenging to measure. Learning how to get press is an area where I think we really need to improve.
What were we able to do to cause spikes?
DLC: Meh
The board game Hive has 3 expansion pieces. They each significantly change gameplay and took a while to make, so after we launched the game, we got into creating & releasing those as soon as we could finish them. Each launch resulted in more visibility on Steam and drove sales of the main game. Steam users all seem to hate DLC in a different way – I’m fairly convinced that there is no way to do DLC that users agree is the right way… they will always be mad – so it’s always stressful. We lucked out since we’re making a digital version of a board game that exists in stores (and has actual expansions) so we did a direct analog to that sales system. This means we had a system that at least we feel good about. Judging by the sales of the expansion pieces, I think people understood our reasoning overall, but if we got a lot of flack for this system, be aware that you’re likely going to get a lot of complaints for your DLC regardless of what you do. It’s just not something that gives players warm-fuzzies and we’re in an industry where warm-fuzzies and happiness are a large part of what we’re selling. Another caveat is that there is a bit of a limit on how many you can do, so this isn’t a good strategy for getting a bunch of spikes over the long-term. We did the 3 expansions and that seems to be the limit of where it makes sense for our game (unless Gen42 Games releases new expansions for Hive in the future).
Mac & Linux Launches
After Hive, we’ve been launching all games with Mac & Linux from the get-go, but originally we didn’t have the porting figured out. For Hive, we launched the Mac and Linux versions about four months after the full-launch of the game.
An interesting side-effect was that the game showed up in “New Releases” on Mac and Linux pages of Steam. This, coupled with a 20% off sale on the game (which matched our initial launch-week price), seemed to drive a fairly big week-long spike for the games. The launch-spike for games overall is usually much shorter, but as of summer 2014, it was taking a week for a game to get knocked off of the New Releases list on Mac. That list is probably also flooded by now (but less than for Windows), so your mileage may vary.
As you can see from the charts, not only did they cause spikes, but they ended up being an additional source of revenue equal to almost 12% of our total revenue for the 2 year period since Hive’s initial Early Access launch.
Discounts
Running sales gives you more visibility on Steam, and honestly many users have probably added your game to their wishlist and are just waiting for a sale.
Sale prices have become the norm on Steam. Due to international exchange rates and grouping of items into two-packs or Complete Packs (bundling the game with the expansions), it’s a bit tricky to calculate a perfect representation of how cheaply things sell. However, in the United States a single copy of Hive is $9.99 and a two-pack ends up being ~$7.99 per copy, and if you get a single Complete pack it can get as high as $15.99 per copy. If you take all of the copies we sold and divide by the total revenue from these games (this excludes revenue from DLC that was sold separately), it ends up at at an average of $3.62 per copy.
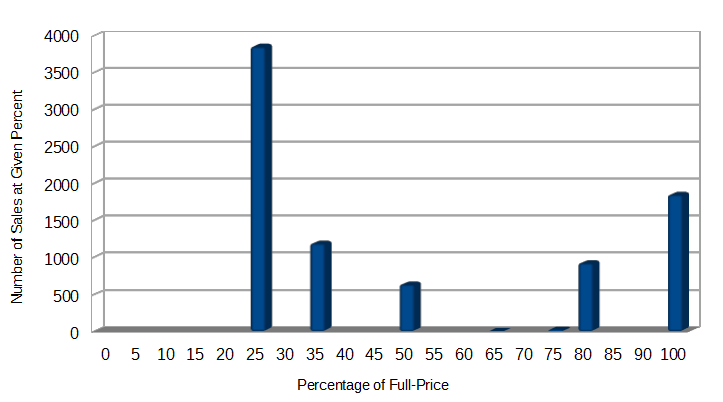
Since we have so many different starting-prices, perhaps a more useful way to grasp the exact impact of sales prices is to see a histogram of volume of sales at given percentages of full-price. For example, this chart is showing that we sold about twice as many units at 75%-off (25% of full price) as we did at full-price. The chart doesn’t show the total revenue, so since 100% is 4x the revenue-per-copy that 25% is, then we still made about twice as much money on full-priced copies as heavily discounted copies.
Side-note: There are sites like SteamDb that track the price-histories for games, so don’t do any crazy 90% off experiments early on in your game’s lifespan or users might hold off on buying your game, expecting it to go to that level again. If people expect to pay 20% off full-price at launch, then slowly get discounts over the following months then users will be motivated to buy now if they can. Hopefully they will only wait if they’re price-sensitive enough that a few months are worth a few percent to them (we’ve all been there). This ends up working out pretty well for everyone.
Updates, updates, updates!
When updates are announced in conjunction with sales, they lead to more units. We often announced an update in the middle of a sale-week and saw a second peak. This also indicates to potential buyers that you’re not just discounting an old, stale game, but are just selling a game that’s both mature and still growing. Even when we’re not doing sales, we do a quite a large amount of updates.
Bundles? Not yet!
Since this post is referring to how we sold more units in Year 2 than Year 1, many people might have assumed that the answer was one word: Bundles. In fact, we haven’t done any bundles for Hive yet. Hive is a premium niche product and we’d love to see it in an appropriate bundle (such as a Humble Digital Tabletop Bundle) some day. In the meantime, all of our growth was done just based on selling it on Steam, the Humble Store, and via the Humble Widget. Pay-what-you-want for Hive sounds pretty enticing, huh? 😉
We put some of our other games in non-Humble Bundles a while ago. The revenue was negligible but dumping thousands of copies did a good job of beefing up the online communities so that there were always more people online.
Other Big Learnings
These weren’t directly related to sales spikes, but we learned a thing or two…
Be responsive to the community!
I read every forum post for all of our games (even Simply Chess which took me about 10 hours per day right after launch) and respond to almost all of them. Being present (so that users know you care) and doing bug-fixes and forward development based on their suggestions ensures that you have a product that’s actually going in the direction the market wants and it lets users know that you actually care about them even after you have their money.
As a caveat: I’ve never tried ignoring the community so I really don’t have a scientific comparison to say that this has been more useful than doing the opposite (being a jerk and completely ignoring your users). Anecdotally though: several of our Steam Reviews have mentioned that part of what they liked about our games is that we’re so responsive in the forums.
Full Launch > Early Access
Our Full Launch sold a lot more units than our Early Access launch which is the opposite of what I’ve been reading in a lot of places. This might be due to our lack of press – I’ve read that press view your Early Access launch as your only launch because your game is “old news” by the time it comes out. Another possibility is that this could just be because our Early Access launch was over 2 years ago and things may have changed since then. Your mileage may vary.
Keep grinding to build the online community
If your game has multiplayer, build the online community. If a player goes on and there is nobody to play against, they quickly abandon the lobby assuming “nobody is ever online” and then another person may come in 5 minutes later and think the same thing. This means that there is a specific tipping point where there is always someone to play with, which keeps both of those players online longer and when the next person comes in, they also see an active community and stay online playing. It is a really long arduous journey for an indie, but keep iterating until you pass that tipping point. We spent months of development on this before we started to see it pay off. We reworked the Online Game Menu Screen, wrote our own group-chat, etc. but it wasn’t until we released Asynchronous games (which took a lot of work) that the online community really started thriving.
Other Small Factors
We’re using the same engine for all of our games which subsidizes bug-fixing and new features.
If you have a thriving online community, it seems to raise the daily sales at full-price. Even though it’s not a ton of sales, 5 sales per day for a month (between spikes) is much better than 1 sale per day for that month. It adds up.
We’re fairly niche since we make turn based games. If you’re not niche, you might get better results from PR and even more viral growth from an online community.
Some sources of error in the data: these stats were just from Steam. This ignores the Humble Store and Humble Widget sales just for simplicity of pre-processing all of the data to make these charts. Also, we mainly used units-sold rather than total revenue. The raw revenue was pretty flat Y1 vs Y2. There are a lot of different currencies so I presented the data as percentages-of-full-price in some spots. The actual amount earned per unit is much less clean due to the variance in currency conversions.
Change is constant. The Indiepocalypse isn’t some big one-time shift in the industry. If you read The Ultimate History of Video Games (great book), you’ll realize that change is extremely normal in game development. The entire market has been changing every couple of years since its creation. The fact that Steam has been a solid place to market your game for many years in a row is actually a fairly impressive amount of stability. Get used to change and continually run tests to figure out what the current state of the world is.
I’m so bad at marketing that somehow, I’ve gone this whole post without asking you to buy Hive! Please buy our game: Hive on Steam.
Conclusion
The indie dev market is (and has likely always been) crazy. Making a good game is absolutely mandatory for success but despite what you read, it is never enough on its own.
By running your own experiments, tracking metrics, and learning from the experiences of other developers (eg: reading what I’ve written above!) you can survive despite the challenges of the day.
It’s always the Indiepocalypse. The Indiepocalypse never changes.
Our fourth game, “Simply Chess” is now available on Steam!
It’s just what it sounds like: Chess! We wanted to stick to the basics, but to provide a ton of play modes: local multiplayer, pass-n-play, 100 Levels of AI powered by the Stockfish engine, online play, and async play (correspondence chess) w/Steam Notifications. We are also striving to make it widely accessible, so we’ve released on Windows, Mac, and Linux simultaneously and we support keyboard/mouse/gamepad interchangeably at any time.
We launched it just less than a week ago and were immediately surprised by the amount of traffic it got. In one day, it had doubled the number of downloads that our previous best-selling game has gotten in 1.5 years!
With this army of 10’s of thousands of testers, the community was able to find a ton of bugs and feature-improvements so we’ve been pushing a bunch of updates nonstop! Steam handles the upgrade-process so new versions only require downloading about as many bytes as you download when you hit a website… so we’re releasing quite often.
The way this game works: all features are totally free! After you’ve played a couple of games, you’ll get a 7 second cross-promotion before each new match. The cross-promotions are just ads for one of the other three digital tabletop games that BlueLine has released on Steam. If you’d rather not see the cross-promotions or want to send us a couple of bucks as a thank-you for the game: you can upgrade to Premium for $4.99 and you won’t see the cross promotion again.
Also, as a special thanks to our loyal fans… if you own all three of our other games, we will be updating the game so that you don’t see ads (basically: you get Premium for free).
We just want to say thank you to everyone who’s been playing & who has given us feedback on the game! It’s been a wild week and we’re expecting to cross the 100,000 downloads mark today!
Making your own game servers is fairly significant undertaking, so now that we’ve released our own game servers and started using them for our games – Hive, Khet 2.0, and Reversi – I thought I’d share a brief postmortem to help anyone else considering going this route at some point.
Why host your own Game Servers?
Obviously, a good starting point is to determine if it even makes sense to host your own game-servers. Our first releases, “Hive” and “Khet 2.0” both shipped using Steam’s networking. In fact, Hive had a previous version running on Xbox 360 which used Xbox Live.
Most common platforms have some built-in networking. Unfortunately, even if you use something like Unity, you’ll spend a lot of time cramming in each platform’s different concept of networking into your game. More on that later.
All of these platforms take a while to integrate but significantly less time than writing your own servers from scratch. They’re usually free to use, and are built to scale to many users.
Due to the time-savings, my recommendation is: start off using the networking on the platform you plan to release on, unless you have a strong reason not to.
Games are not a sure thing, so don’t go investing in making your engine flexible before you’ve found out that you’ve made the right game(s)! If it turns out you were right & there actually is some demand (like there was for our board games), you can spend the months re-writing while players already have your game and are enjoying it. Also, you’re probably earning some income during this time which can help fund the creation of your game servers.
So what would be a good reason to write your own servers? Here are the main reasons that impacted my decision:
Technical limitations: Neither Steam (nor Xbox Live, if I recall) had support for asynchronous play: allowing a game to persist even while neither player is online. This type of thing was really important for turn-based games like ours.
Cross-platform capabilities: Our games were already cross-platform in the sense of being on Windows, Mac, and Linux… but they were still tied to a single gaming platform: Steam. This is currently only available on desktops / laptops / SteamOS Consoles, but wouldn’t it be cool to be able to play from PC to mobile some day? In a game without coordination (like turn based games) it is completely fair to play across these form-factors without giving either side an advantage.
Minimizing re-writes during massive porting: We didn’t have to rewrite our code to make our Mac and Linux versions of our games, they all ran with Steam. However, if we expand to mobile in the future, or go back to consoles again, we’d have to re-write to iOS’s Game Center, Google Play, PlayStation Network, etc.. With our own game-servers, not only will players be able to compete across those systems, but we won’t need to do a rewrite! As long as the system gives us access to make http requests, we’re all set!
More DRM-free: Many gamers are cautious about buying games with DRM because they’re afraid that petty corporate overlords are going to arbitrarily yank their access to the product they legitimately purchased. It has happened plenty of times in the past. While we haven’t added any DRM to our games (and even created a DRM-free mode to make the game run as smoothly as possible even without Steam), we were still bound to requiring Steam for Online Play. Now we don’t use their game servers. We currently still use Steam Lobbies, but once we write those out, we will have no requirement for any 3rd-party platform at all. We’ll be completely DRM-free. #feelsgoodman
How does it work?
This section will be a brief overview of how the system actually works.
Connecting Steam Players to BlueLine Cloud
It should be very simple for users to get playing. An experience that I enjoyed as a gamer was PlayFab’s signup for Planetary Annihilation. So I modeled our signup after that (it’s a single, small form that you only ever see once). Apparently, I oversimplified a bit by going this route (see: Mistakes section below), but it felt solid & was a decent starting point.
The form gives the option to add an email address and password. This keeps the data from being locked into your Steam account. Additionally, we’re keeping the door open for letting users have email alerts when it’s their turn (Steam Notifications are great, but you only see them when you’re on Steam).
After the initial setup, we use the user’s Steam authentication to automatically connect them in the future. Keep in mind: even if the user does not set an email/password to give themselves unlimited access later, we can still connect them.
Cloud Servers
Fortunately, we have a lot of web-background and have scaled large web-services before, so not having to learn all of that from scratch saved a ton of time.
We ended up structuring the system to run on Cloud Servers. That’s a fancy name meaning that you don’t own a specific piece of hardware, but rather you’re assigned a certain amount of resources & that can bounce around as some machines fail and others start up. They are easy to scale up, and in our case they happened to be the least expensive introductory option also – which is great! I’ve been pricing and re-pricing them since AWS’s early days, hoping the scales would finally tip!
We’re paying in the ballpark of $20/month to start out, and things are running smoothly. If things start to slow down, it’ll likely be another $20/month for more power, and so-on.
Update: Someone asked about the exact stack. It’s a private hosting company I’d worked with before, and my starting instance is 2GB Ram / 2 CPUs / 1 dedicated IP (need it for some SSL stuff we do). It’s not an “image” like in AWS, the server just spins up running CentOS, so I will configure new instances with normal bash scripts.
The actual stack of the game-servers is a REST-like PHP API that’s backed by a mySQL database.
Game Data
Instead of storing the data in some custom format, we wanted to make sure the data would be easy to use across very different platforms, and even publicly accessible at some point.
Therefore, we stored the “game settings” in JSON blobs, and the “ply histories” (the list of plays that the players have made in a match) are in the most standard format we could find for each game.
This makes the data human-readable in the database (easier for debugging) and more standardized so down the road we could open an API and people could make their own game-reviewing / visualization / statistical analysis programs easily.
We rolled this out with Reversi (a new game with a smaller audience) then fixed it a bit and rolled it out to Khet 2.0 (which is a few months older and has a bigger audience) and then we got more feedback and did more fixes before rolling it out to Hive which is our oldest Steam game and has the largest built-up audience.
Fortunately, I think we ironed out most of the wrinkles before the Hive release, but here were our most notable errors.
Communicating about Accounts
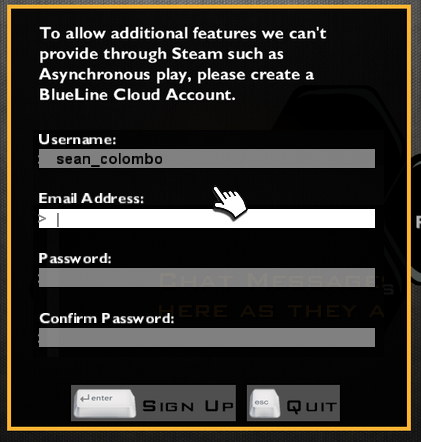
When we updated Khet 2.0 to have async, we got some users really upset because they had mistakenly thought we added DRM.
This blind-sided me a little because the dialog only asked for an email address and a password, which I thought were super-ubiquitous these days. I think it was mostly a visceral reaction to seeing a dialog box with the name of our game servers “BlueLine Cloud” on a game called “Khet 2.0”. If they didn’t notice the “BlueLine Game Studios” splash screen, that sounds like it might be a third-party. For all the user knew, this third-party might be sending an email-confirmation link to that address (so it would have to be valid) and then using it for nefarious purposes.
Keep in mind, this dialog was mostly well-received, but if the experience is super negative for some of your players to the point that they’d quit playing your game (which this user would have if we hadn’t been able to explain things better in the forum), it’s worth reworking. Not all of your players will be willing to go out of their way to express their disappointment when something is broken. So if you hear something from two users, it’s likely that many more had the same thought.
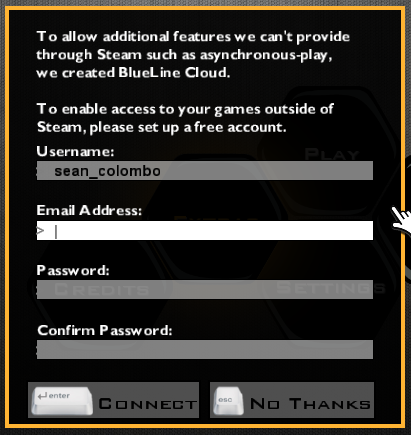
We reworked the entire signup so that you never have to give us an email/password if you don’t want to. Furthermore, if you change your mind, you can set up the email/password combination later-on.
Even though the underlying system is the same… we think that changing the wording and making the “No Thanks” option will keep players from being scared, confused, or otherwise inconvenienced by the dialog.
Initial version:
Improved version:
The second one is much more clear that the email address really is optional and it’s only UNlocking your data, not adding additional locks.
Estimation!
Still in the “what we did wrong” section. You may hear “estimation” come up as a weak point in many post-mortems… but that’s something that we’re actually usually quite good at. I’m not being glib here, our side-business (that we originally made for internal use) is a Burndown Chart tool for Trello. I married a Project Manager / Scrum Master. …estimation is usually one of those things we really excel at – because we actually nerd out on Project Management a bit.
However, this one went way off the rails. In late January, here’s me embarrassingly announcing that it would be out in a couple of weeks. When I tease launch-dates I tend to build in some buffer for things going wrong (and I had done just that). In the end, I underestimated the hours for the initial release by a factor of three! Furthermore, there were so many finicky edge-cases, that we ended up completely changing the rollout plan. We first rolled out on our new game Reversi (which has the most simple “plyHistory” format, so it was the safest), but then we saw that there were a bunch of things that needed to be changed or improved. It took weeks to finish those bugfixes & improvements and roll out on our next most-complex game: Khet 2.0… then we had external causes that made us delay making such a large (and therefore risky) update to Hive… so we polished it for a couple more weeks.
In the end, the Async that was teased to come out in “a couple of weeks” just came out May 26th, four months after that announcement. Someone fan me down, I’m blushing!
This experience hammered into me what might be a law of physics: when doing anything with networking, make a really conservative estimate, then triple it. Then plan for additional time for bugfixes after launch.
Xbox networking, Steam networking, and even writing our own gameservers, all took way longer than expected. These type of tasks aren’t the sum of their anticipated parts because you will fall into several rabbit holes where you can spend days debugging things that make no sense at all.
Furthermore, documentation always seems to be horrible for anything networking related. My guess is that there just aren’t many people who end up using it very deeply. People design the systems, do some Hello World apps while they write the docs, then the broad & wild internet makes a mess of our perfect theoretical world!
To reiterate: For anything related to networking: estimate conservatively, then triple it.
Conclusion
I hope that gave a good general overview of the types of things we had to do to switch to our own game servers, why we did it, and what this lets us do in the future.
If you have any questions, feel free to leave comments here or contact me through any of the other methods on the site (these days, I’m pretty accessible through twitter too @bluelinegames).
Sometimes, you may need to slow-down your framerate to test certain behavior in your game/app as it would appear on really bad hardware. The following snippet lets you easily tweak a framerate at runtime.
Since Update() gets called every tick, just put this in any GameComponent and you should be good to go. Press “+” to increase the delay (and thus decrease the framerate), or “-” to decrease the delay.
You can comment out this whole method when you’re not using it, or just leave it like it is so that it only builds in DEBUG mode, etc..
#if DEBUG
static int millisToSleep = 0;
protected override void Update(GameTime gameTime)
{
KeyboardState newKeyState = Keyboard.GetState();
if (newKeyState.IsKeyDown(Keys.OemPlus))
{
millisToSleep += 5;
// REPLACE THIS WITH WHATEVER SYSTEM YOU USE FOR NOTIFICATIONS:
//MessageBoxUtil.Notify("SLEEPING " + millisToSleep + " PER FRAME");
} else if (newKeyState.IsKeyDown(Keys.OemMinus))
{
millisToSleep -= 5;
//MessageBoxUtil.Notify("SLEEPING " + millisToSleep + " PER FRAME");
}
if (millisToSleep > 0)
{
System.Threading.Thread.Sleep(millisToSleep);
}
}
#endif
Today, we’re releasing some Open Source freeware! As part of creating our next game (Reversi for PC, Mac, and Linux on Steam), we wanted to make use of some of the great AI that’s already been written for Reversi over the years.
One of the most respected Reversi AI programs is WZebra by Gunnar Andersson. WZebra hasn’t been updated since around 2005, but it was released under GPL and included a command-line tool for solving the end of a bunch of games (scrZebra) as well as some other analysis tasks. What it didn’t include, was a way to access WZebra’s AI via command-line to easily get the best move for a specific board layout. That’s exactly what BlueZebra is: BlueLine’s customization to allow command-line access to WZebra AI.
Here is a zip of the project: download BlueZebra*. Since it is based on a GPL project, it is itself released under a GPL license. To make changes, use the Visual Studio solution and recompile. We also updated the Makefile to work with modern systems (it was made when everything was 32 bit) and made the Makefile compile on OSX, not just Linux.
Run “blueZebra.exe ?” to get help info for each of the parameters, but to give you an idea of how you can pass everything in & get back a move from the AI, here is example usage:
prompt> blueZebra.exe -cli -b 1 -e 0 -line 2 -scores 0 -depth 24 26 28 -board -----X------X------XOX-----OO-----OXO------X-------------------- -turn O
c6
“c6” is the move that the AI returned for White to play.
*: hashes of the zip file…
md5: af7733545b7bb21aed9399c5f3f08f6d
sha1: 30b7d0379f318c6974460d066944a11fcc3215fe
I often hear the question of why there aren’t more board games on a certain platform. The short overarching answer is just that digital board games are a niche-market, so big game companies aren’t often willing to take the risk of making them.
However, I think there are some hints as to where board games will start showing up in the near future.
I’ll be working with the assumption that other than a few outliers (Monopoly, Risk, etc.) that are made by EA or some other huge publisher, most digital versions of board games will likely be made by indies.
Consoles?
This is a complicated one, but I think that we’re not going to see many new board games on consoles in the near future. The old-gen consoles were a mixed-bag for independent developers. Xbox 360 was really the only one that indies could easily get into. BlueLine could probably get into all of them at our current size, but it excludes any first-timers. Additionally, after Microsoft announced that they were no longer supporting XNA, the amount of games that sold on Xbox Live Indie Games (their deeply-hidden indie channel) dropped off a cliff.
What about the current generation? Sony has gone out and recruited a bunch of indies to build games for the PS4… but I doubt they’ll continue doing that much longer after launch – they’re flat-out funding games and that’s a big financial investment. Xbox is again trying to be accessible to indies with their “ID@Xbox” program (which we’ve been accepted to), but there are two major things holding back board games from Xbox One*. First: it’s expensive. Unlike other indie-friendly locations where the startup costs are around typically a couple of hundred dollars, a very lean Xbox One indie game runs upward of $5,000. Secondly, even in 2014, Xbox 360 still has about twice as many sales as Xbox One. A market with high costs and low sales isn’t great for niche games. It’ll be a while before the install-base of new consoles grows enough that a bunch of board games start popping up on there.
PC, Mac, Linux
There are a decent number of board-games coming to PC (especially on Steam) over the past year or so. I think more will continue to show up, just slowly. We released Hive and Khet 2.0 this year, and just our two-man team still hasn’t been bumped off the list of 10 Newest Releases tagged with “Board Game”. It’s entirely possible that our next game, Reversi will bump Hive off of the most-recent list, if no new board games come out in January or February.
PC, Mac, and Linux are probably the best platform for selling digital versions of board games at the moment.
Mobile
Smart phones are a great form-factor for many board games, and a bunch of games came out over the year since they became popular. However, many have had a rough time with sales in recent months/years. Most digital board games are made by fairly small devs: we survive on the Steam store’s visibility and we’d have a really rough time in mobile because you need to be on the “top downloads” list to get any traction there. Board games are usually too niche for that to happen organically and it’s too expensive to buy the number of downloads needed to fake it. This “faking it” is the current modus operandi for most mobile games. They buy huge amounts of downloads (via ads in other games) and hope that it generates enough of a following to get them to the Top Downloads list where they get to see if they’ll actually get traction. That’s usually not a great strategy for board games!
Tablets
Board gamers often lament the lack of titles on tablets – which seem like the most ideal medium for digital board games. However, I think that’ll happen even more slowly. Even though tablets are a fantastic device for playing games, the market is currently (unfortunately) just an afterthought. The games on there now are mostly because it’s easy to go to tablets from a mobile game. However, the market for tablets themselves are really small (around $3.6b compared to about$20b for PC). The reason market-size matters is just that it’s an indicator of how many games you can sell if you have great exposure. Tablets are a just a very small market at the moment, and aren’t expected to catch up to PC for about another 5 years.
We’ll get our games on tablets eventually… but it’s going to take a while. Hopefully not more than a year or so!
HTML5
It’s really hard to monetize a straightforward board game in HTML5 at the moment. If you saw Goko (who got the license to Dominion) and thought that they would ever be able to earn enough to support their big dev team & pay back all that venture capital… you probably weren’t paying attention to the margins in this industry. 😉 Nobody has made it work correctly yet. The only board game sites that are currently surviving seem to be those that don’t make any money & don’t pay any royalties. Since most of those are hobbies, you can probably expect a handful of very basic implementations to continue to come out… just not with paid licenses.
The Future
What I’m most excited for in the future is cross-platform online play. It’s super time-consuming to get it working (in part because you literally need to create the game multiple times**) but it should be a lot of fun and make it easier to find online games with other people instead of having an already-niche community silo’ed across several devices, as is currently the case with Hive which currently has different 5 different online communities.
Do you know of any digital board games coming out in the near future? Let us know in the comments below.
*: There are actually three, but one of them is technical and it’s covered by an NDA so I can’t talk about it until it’s fixed.
**: I realize that Unity/MonoGame/etc. take a ton of work away from porting, but if you want the game experience to be really good, it should be designed once for consoles (with gamepads) then another way for PC/Mac/Linux (to allow gamepad and/or mouse/keyboard) and have another – probably significantly different – interface for touch/drag devices with unreliable screen resolutions.